
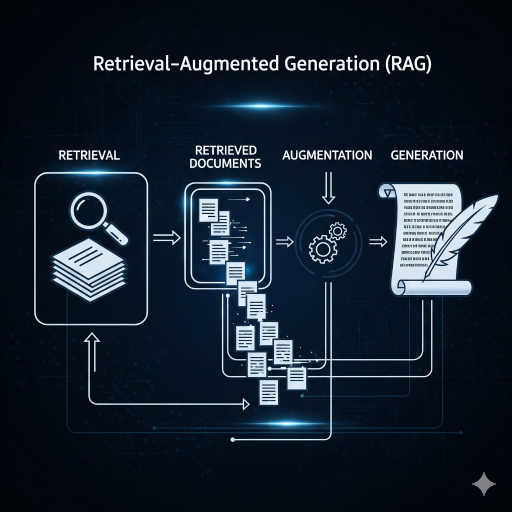
RAG = Retrieval-Augmented Generation
adalah teknik yang menggabungkan database dokumen (retrieval) dengan kemampuan bahasa AI/LLM (generation).
Artinya: AI tidak hanya mengandalkan ingatan model (parameter), tapi juga bisa “mencari dan membaca dokumen” sebelum menjawab pertanyaan.
Cara Kerja RAG
- User bertanya:
→ “Apa aturan cuti di perusahaan kita?” - Retrieval (pencarian dokumen):
- Pertanyaan diubah jadi vector embedding (representasi numerik).
- Sistem mencari potongan dokumen relevan dari vector database (misalnya: SOP perusahaan).
- Augmentation (menambahkan konteks):
- Dokumen yang relevan dimasukkan ke dalam prompt LLM.
- Contoh prompt:
Berdasarkan dokumen berikut, jawab pertanyaan user. [Isi dokumen cuti...] Pertanyaan: Apa aturan cuti di perusahaan kita?
- Generation (jawaban):
- LLM menghasilkan jawaban yang lebih akurat, berdasarkan isi dokumen + pengetahuan umumnya.
Ilustrasi Sederhana
Bayangin kamu punya teman pintar (LLM).
- Kalau kamu tanya hal umum, dia bisa jawab dari ingatan.
- Kalau kamu tanya hal khusus (aturan perusahaan), dia buka catatan/dokumen dulu, baru jawab.
Itulah RAG: AI = otak, Database = perpustakaan mini.
Kelebihan RAG
✅ Tidak perlu retraining model → hemat biaya.
✅ Bisa update cepat → cukup tambah dokumen baru.
✅ Jawaban lebih akurat, sesuai data perusahaan.
✅ Cocok untuk chatbot berbasis dokumen (SOP, knowledge base, FAQ).
Kekurangan RAG
⚠️ Butuh sistem tambahan (vector database: Pinecone, Weaviate, Milvus, atau Elasticsearch).
⚠️ Kalau retrieval salah (dokumen tidak relevan), jawaban juga bisa salah.
⚠️ Butuh manajemen data (dokumen harus rapih & bisa dipecah jadi chunk).
Contoh Nyata
- Chatbot Customer Service → jawab pertanyaan dari dokumen FAQ perusahaan.
- Legal Assistant → baca peraturan hukum sebelum memberi jawaban.
- Search + Chat → mirip ChatGPT dengan browsing, tapi pakai dokumen internal.
✨ Singkatnya:
RAG = cara bikin AI selalu update dengan dokumen terbaru, tanpa harus melatih ulang model.

